Demystifying Link Discovery with Global Configurations
The ability to have linked data and configuration management is a defining feature of IBM ELM and a bit of a mystery to users (especially when things don’t go as expected).
We aim to remove the mystery and aid teams in managing their configuration-managed enterprises without surprises.
IBM ELM uses link discovery to provide bidirectional linking across versioned artifacts. The straightforward idea is that a link is owned by one resource and stored only on one resource to improve maintainability (no synchronization of endpoints needed!). The side-effect of this pattern is that it creates the responsibility of the target to “discover” any references to itself and present it just the same as an owned link.
An example is a link from a Jira Story to a DOORS Next requirement. Jira stores the link and link type on its artifact. It also stores the Jira version(s) in which this link is active. DOORS Next is then responsible for performing a query to ask if any inbound links relate to the requirement within the current context. Then, DNG shows owned and discovered links as the same to the user. This is the idea of link discovery.
Following, we break down these to dispel the magic and remove the surprise of when links appear (or don’t appear)
The Pieces in Practice
In practice, each tool plays a role in the link discovery process. Following the scenario of Jira to DOORS Next, these are the roles the tools play.
IBM GCM
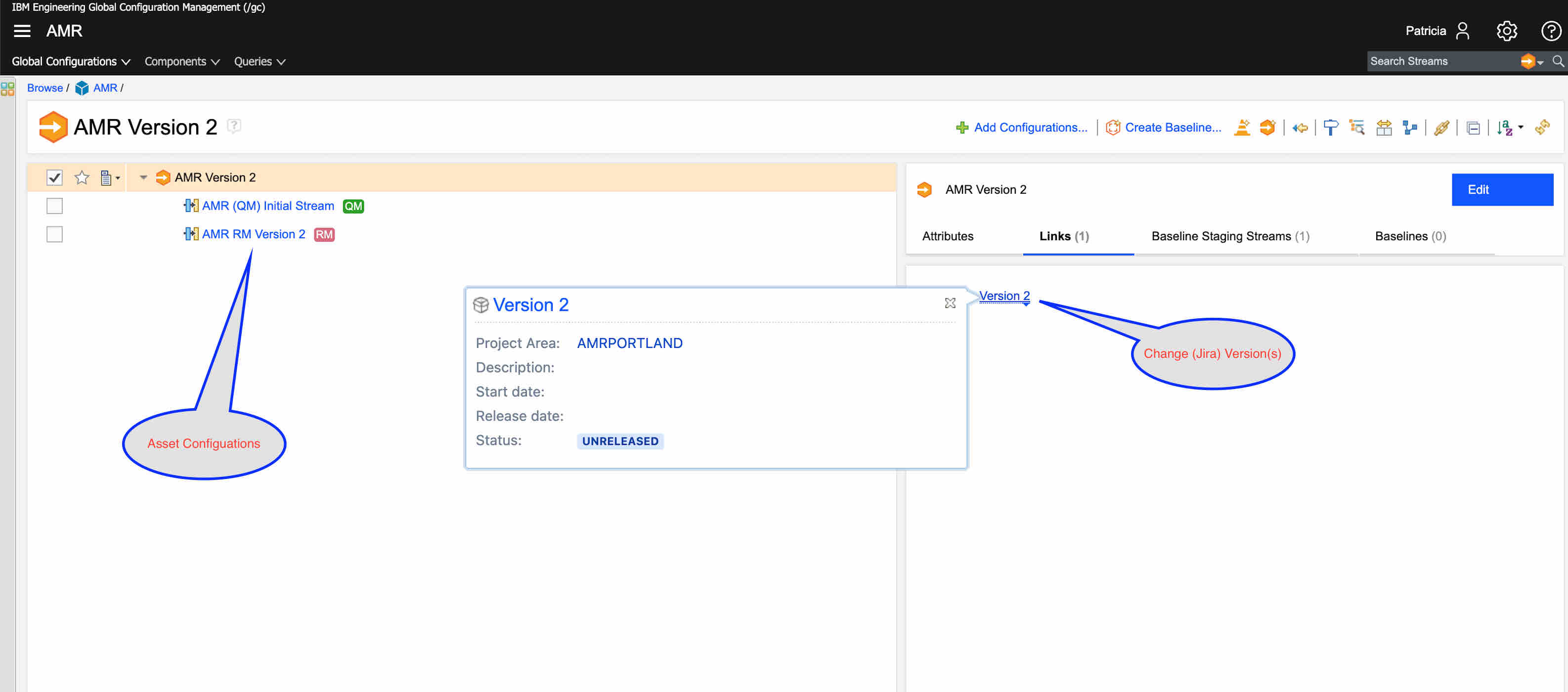
GCM's role is to provide context. It sets the version of artifacts that users want together by selecting a set of local streams of artifacts. In addition, it sets a context for what Jira Versions should be used to select the Jira items of interest.
(OSLC Connect for) Jira
The role of Jira is to define the change artifact, store the link (with a specific relationship), and identify the versions those links apply to. This allows the links in Jira to point to a particular resource in DNG and have the dynamics we expect with OSLC.
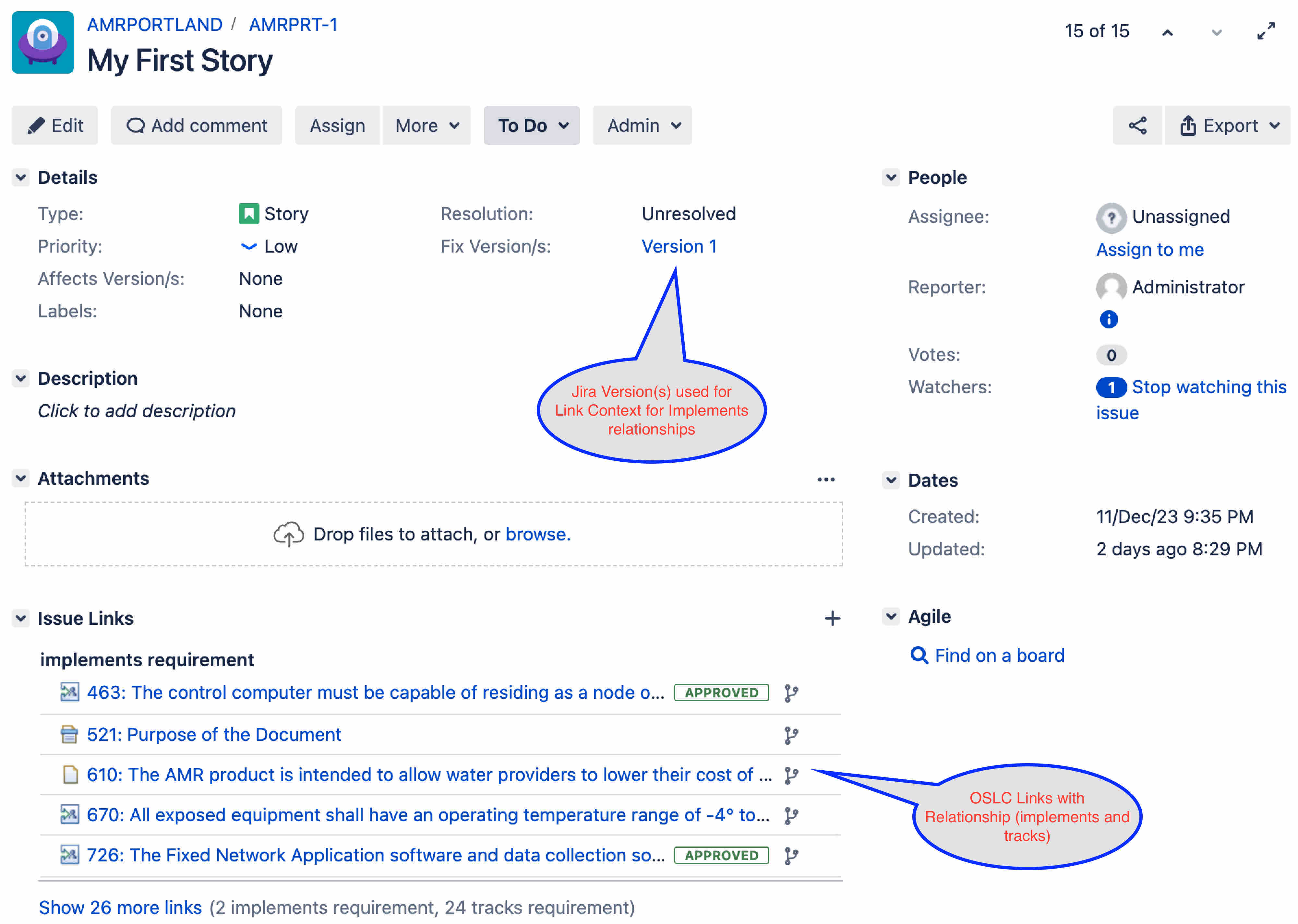
The OSLC Connect for Jira tool is also responsible for sharing the information from Jira so it can be indexed for queries. This is an expression of the artifact, including link and version information.
IBM DOORS Next
The role of DOORS Next is to store requirements and their links. However, it does not store links for change or test artifacts, so it has the secondary role of querying for those artifacts when it displays a requirement.
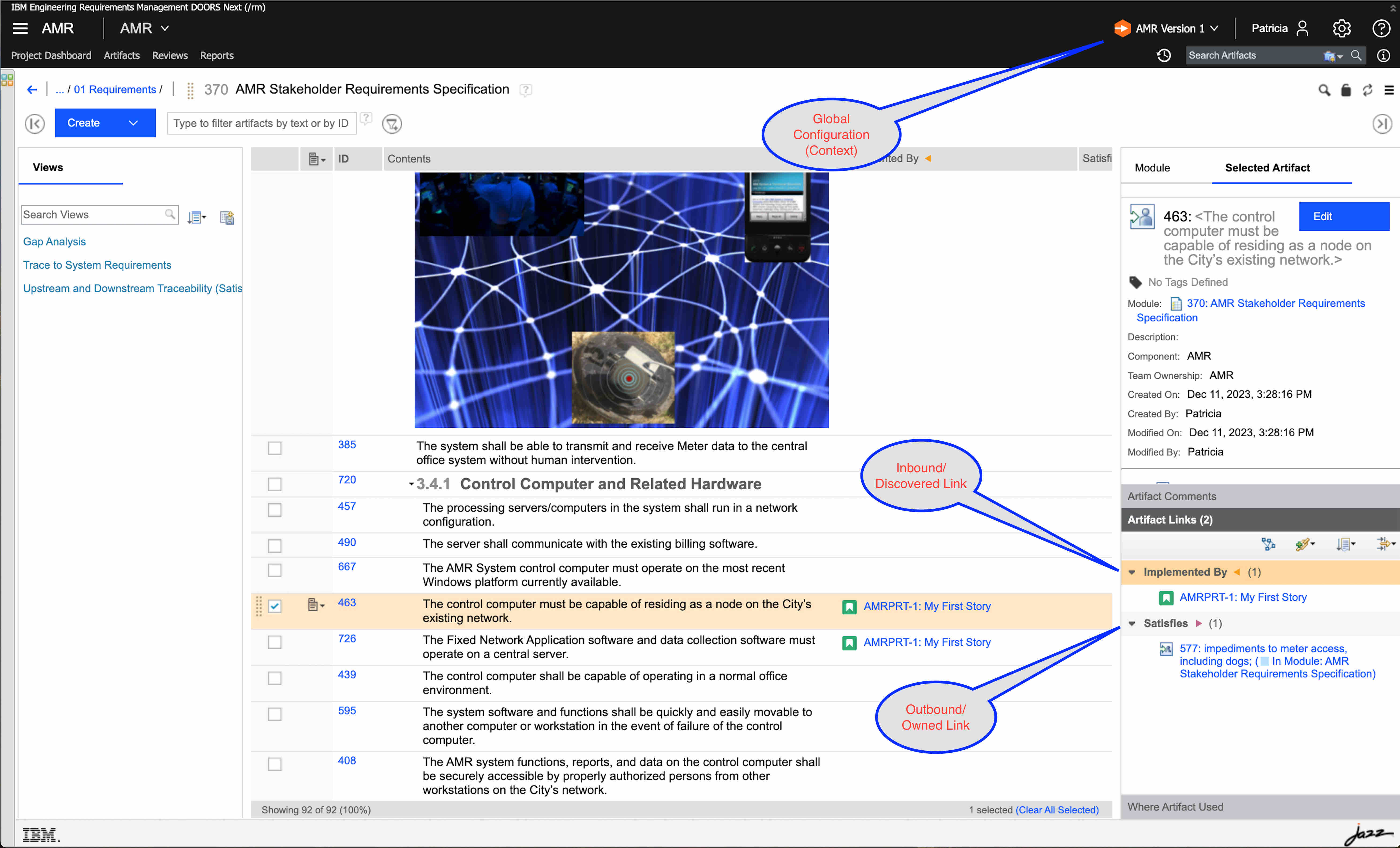
You will note that for performing queries, DNG uses the context of the current GC to formulate the query.
IBM LDX (Link Index Provider)
The link index provider (LDX) reads data sources (like Jira through its TRS feed) to provide query services. In this role, LDX aggregates data from multiple tools to facilitate link discovery. In most deployments, LDX indexes data from GCM, ETM, and EWM. As an additional OSLC participant, we also introduce Jira data.
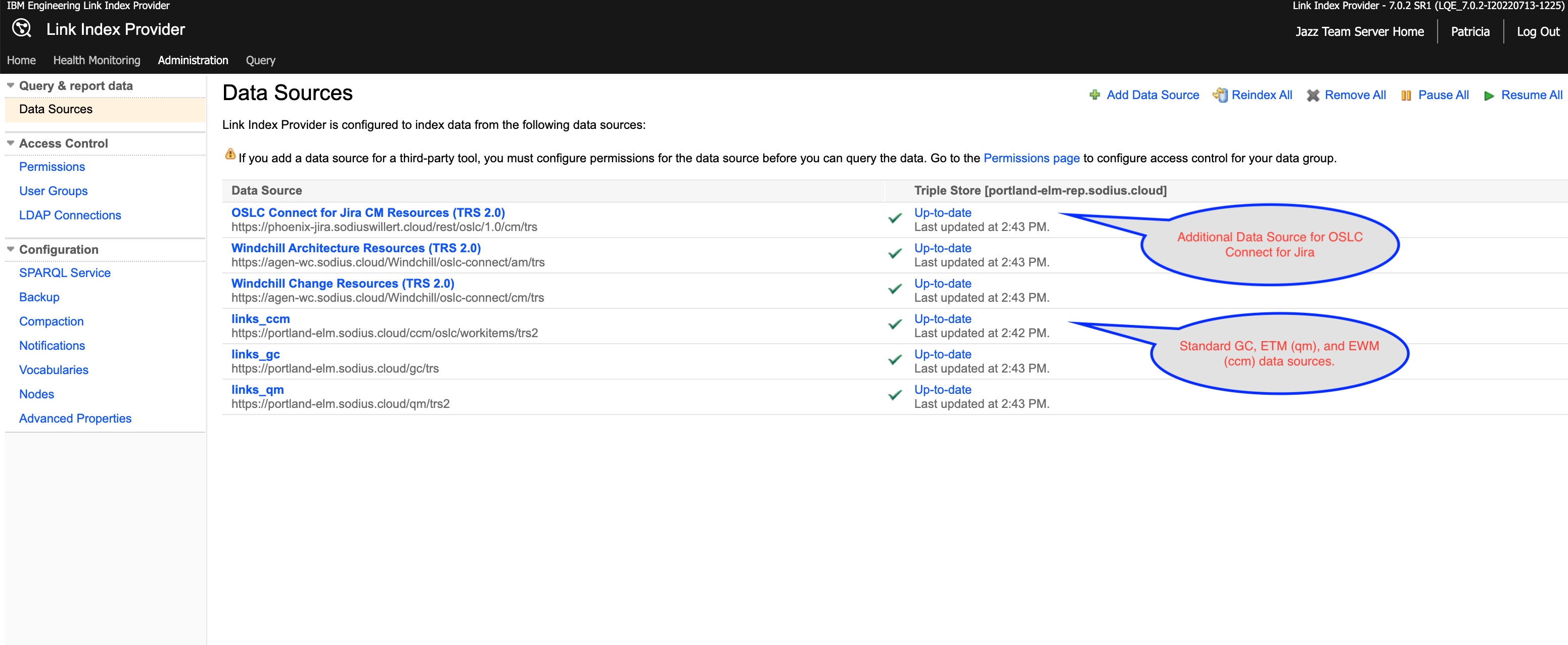
The LDX service provides the query service to identify the information a tool like DNG needs to show inbound links.
A Detailed Demonstration of the Discovery Process
Following is a tour of all of the activities that are executed to facilitate the discovery process.
Feeding the Data
Feeding the data focuses on what information LDX requires to perform the query.
From Jira
Jira is providing two resources to LDX.
First, the Jira issue and its attributes (including links). The attached file is a sample of the raw data of a Jira issue provided to LDX. Note in most deployments, there are thousands if not millions of these artifacts that are read and indexed from Jira.
And the Jira Release. The attached file is a sample of the raw data for a Release that LDX consumes.
The Jira TRS feed tracks these objects for change and identifies when they need to be re-indexed (read) by the indexer as a list of changed artifacts.
From GC
GCM defines the Global Configuration to LDX. Each GC provides a resource description, like the attached, that describes the configuration's contents.
Similar to Jira, the TRS feed for GCM regularly updates with which definitions have changed and must be re-read.
LDX
LDX constantly polls the data sources (roughly once a minute) and updates its index accordingly. By reviewing the documents above, you can see how the index uses the URLs to make connections from a Jira issue to Jira links, to Jira Deliverables, and Global Configurations. This creates a graph of relationships that LDX uses in many different queries.
Consuming the Data
Once the data has been indexed, a given target can use it to discover the links.
Viewing a DNG Requirement, focusing on requirement 463 in module 370. From an OSLC perspective, its identifier is the URL → https://portland-elm.sodius.cloud/rm/resources/BI_z2bQYJhjEe6TI5H6Q2kosw
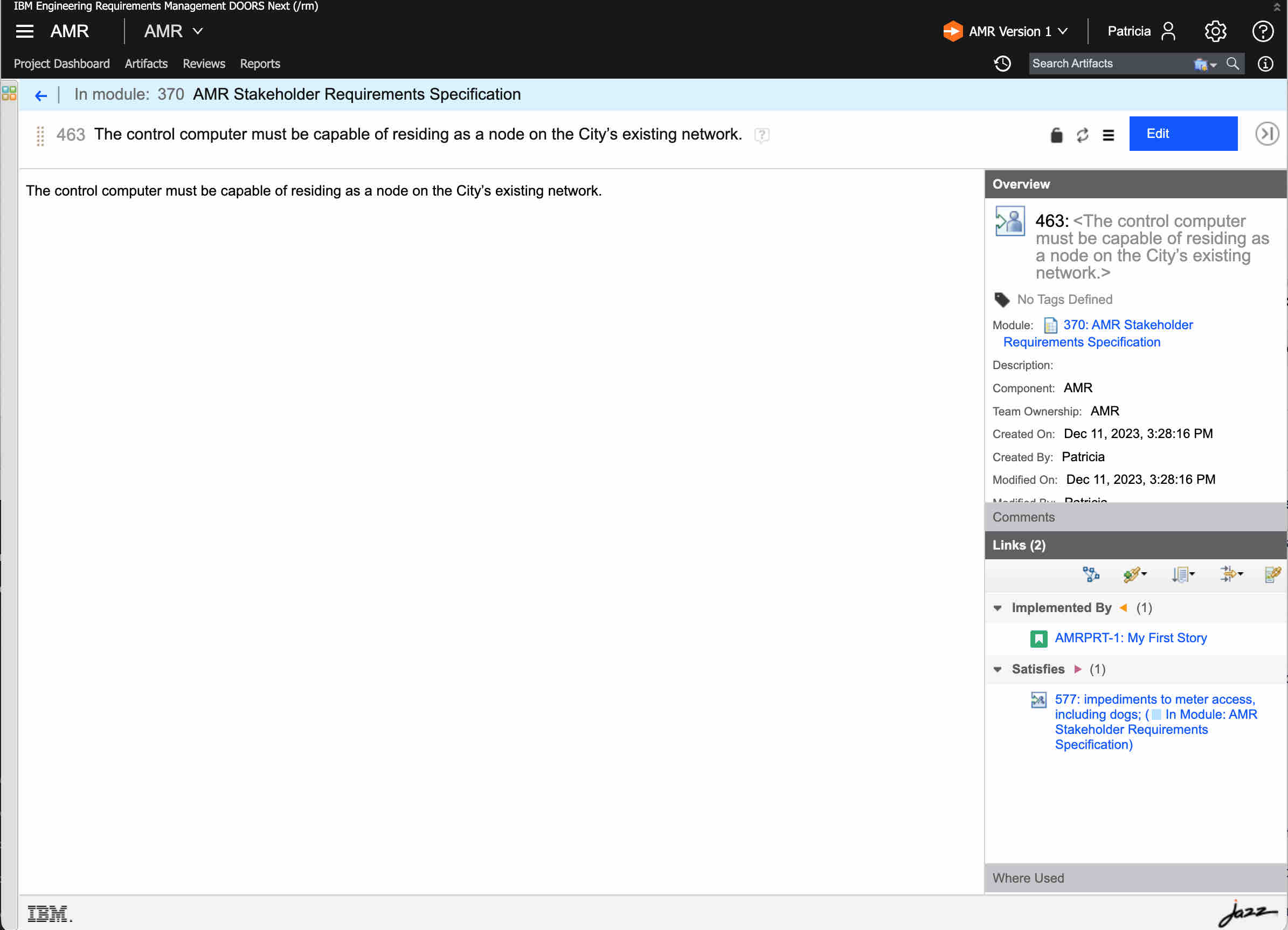
When displaying this, DNG will make two internal requests to find links. This internal REST API (https://myDNGServer/rm/links) has a payload of an artifact URL and a configuration URL. It is called once for this module-bound resource and second for the base requirement resource. The result is the URLs of the links and the relationship type.
It looks like the following:

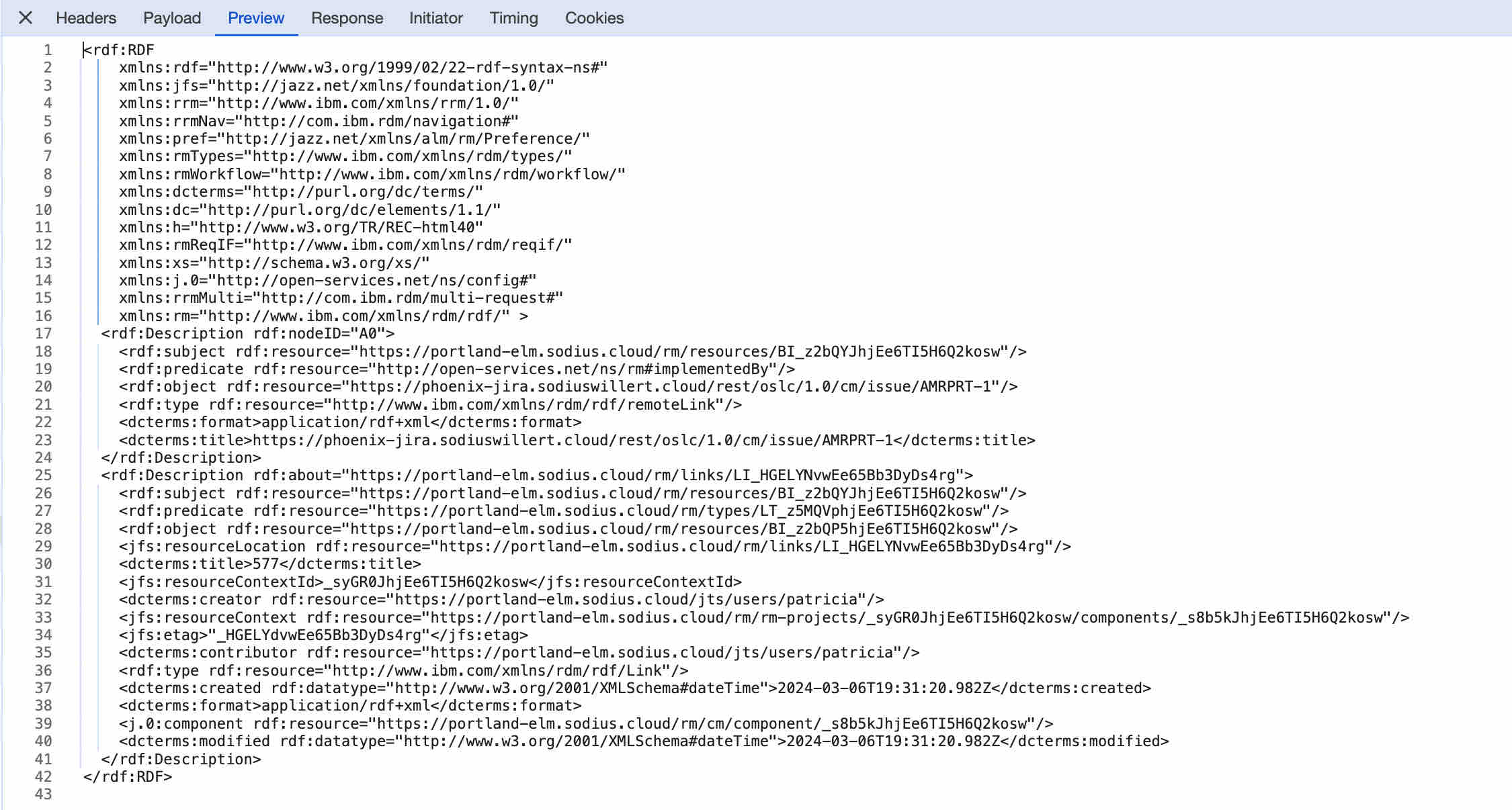
The result includes both discovered and owned links. However to formulate this response DNG relies on LDX for the discovery. This query looks as follows (and can be tracked in LDX).
prefix dcterms: <http://purl.org/dc/terms/>
prefix oslc_config: <http://open-services.net/ns/config#>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix owl: <http://www.w3.org/2002/07/owl#>
prefix rtc_cm: <http://jazz.net/xmlns/prod/jazz/rtc/cm/1.0/>
SELECT DISTINCT ?sURL ?linkType ?tURL ?indLinkType
WHERE {
{
VALUES ?linkType {
<http://jazz.net/xmlns/prod/jazz/calm/1.0/implementsRequirementCollection>
<http://www.ibm.com/xmlns/rdm/types/Extraction>
<http://www.ibm.com/xmlns/rdm/types/Embedding>
<http://purl.org/dc/terms/references>
<http://www.ibm.com/xmlns/rdm/types/SynonymLink>
<http://open-services.net/ns/cm#implementsRequirement>
<http://www.ibm.com/xmlns/rdm/types/Decomposition>
<http://open-services.net/ns/cm#affectsRequirement>
<http://open-services.net/ns/cm#tracksRequirement>
<http://www.ibm.com/xmlns/rdm/types/ArtifactTermReferenceLink>
<http://www.ibm.com/xmlns/rdm/types/Link>
<http://www.ibm.com/xmlns/rdm/types/External>
}
VALUES ?tURL {
<https://portland-elm.sodius.cloud/rm/resources/BI_z2bQYJhjEe6TI5H6Q2kosw>
}
VALUES ?config {
<https://portland-elm.sodius.cloud/gc/configuration/5>
}
{
?sURL ?linkType ?tURL.
BIND( ?linkType as ?indLinkType ) .
}
UNION
{
?indLinkType owl:sameAs ?linkType .
?sURL ?indLinkType ?tURL .
}
}
OPTIONAL
{
?reification rdf:subject ?sURL .
?reification rdf:predicate ?indLinkType .
?reification rdf:object ?tURL .
?reification rtc_cm:deliverable ?release .
?reification rtc_cm:deliverable ?linkRelease .
}
OPTIONAL
{
?config rtc_cm:deliverable/rtc_cm:releasePredecessor* ?configRelease .
}
FILTER (!BOUND(?reification) || (BOUND(?linkRelease) && BOUND(?configRelease) && ?linkRelease = ?configRelease))}
LIMIT 1000
In this, you can see the URL of the module-bound requirement, the link types it is interested in, and the global configuration in which it is interested.
The result is the Jira Artifact which is linked.

This is what we mean when we say discovery. The link isn’t stored on the requirement; rather, a query is issued to “discover” inbound links (all the relationship types in the query).
Note that only the URL of the Jira artifact is returned. To get more details, DNG will request them back from Jira.
Exploring More
If you are looking to understand more, DNG (and QM) to reveal a debug screen to their query service. You can find it at https://myDNGServer/rm/linkIndex/query.
You will see a simple dialog with the parameter of the internal query. The “options” link will provide more details than I describe here.
Add your RM resource URI, the link types you are looking for, and the GC configuration. This service will then compose and request the execution of the LDX SPARQL query.
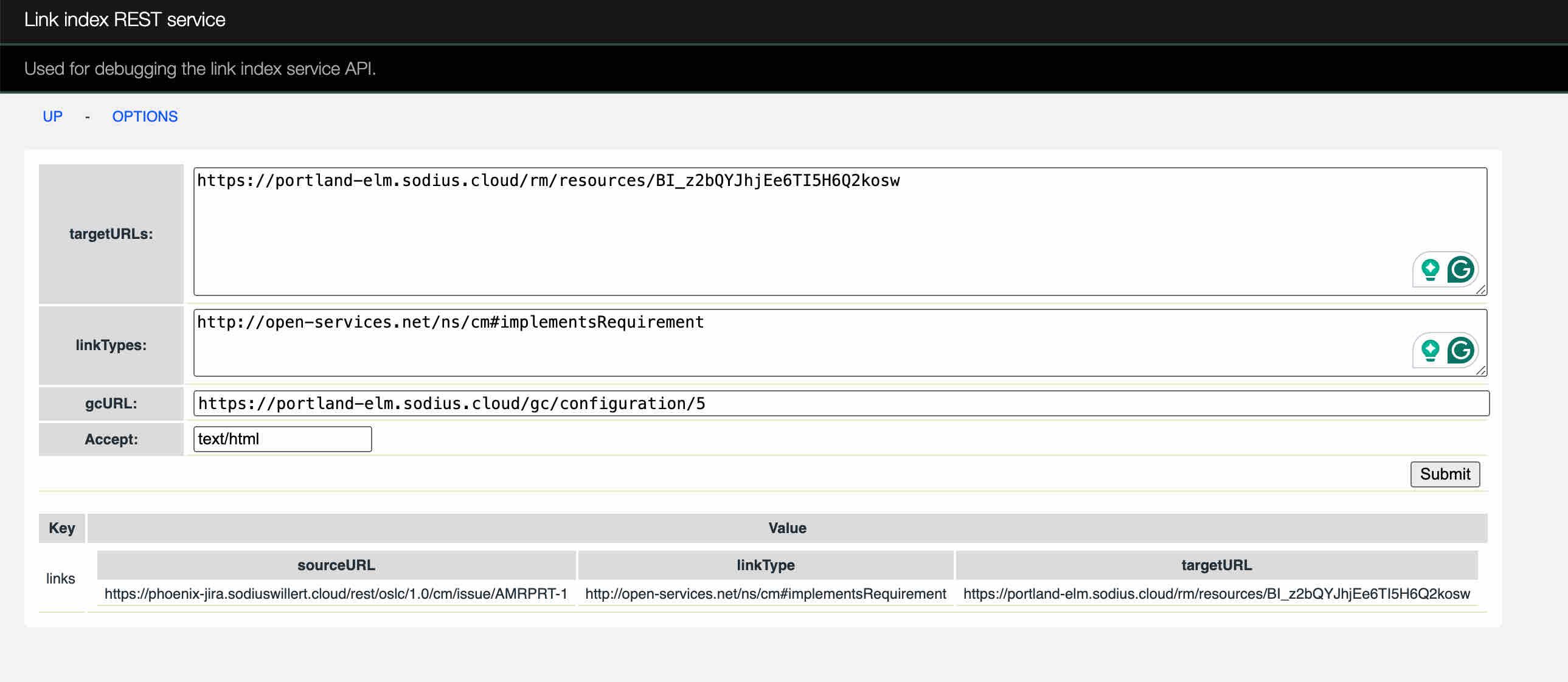
And you can observe the execution in LDX. Navigate to https://myLDXServer/ldx/web/health/query-stats.
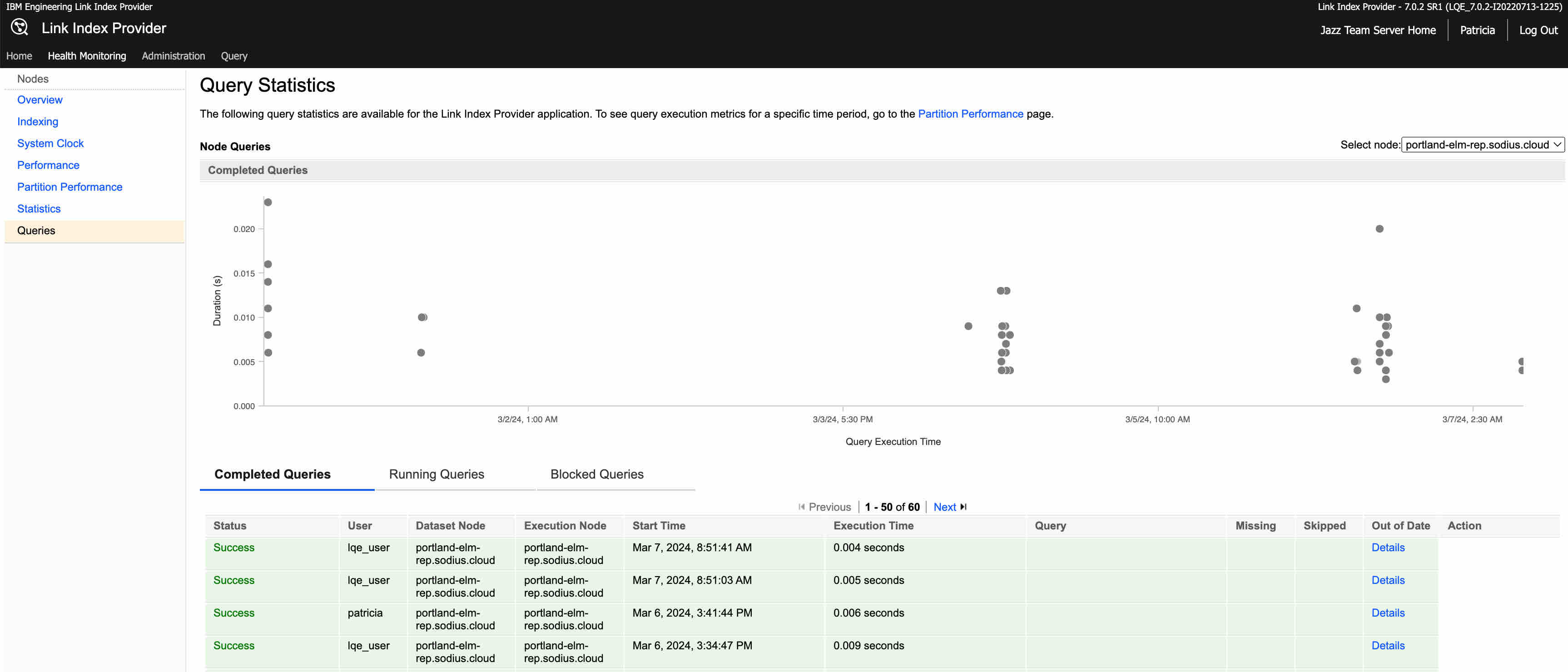
Here, you can review your last queries, performance, and construction. For example, the last query I requested from the RM looks like this:
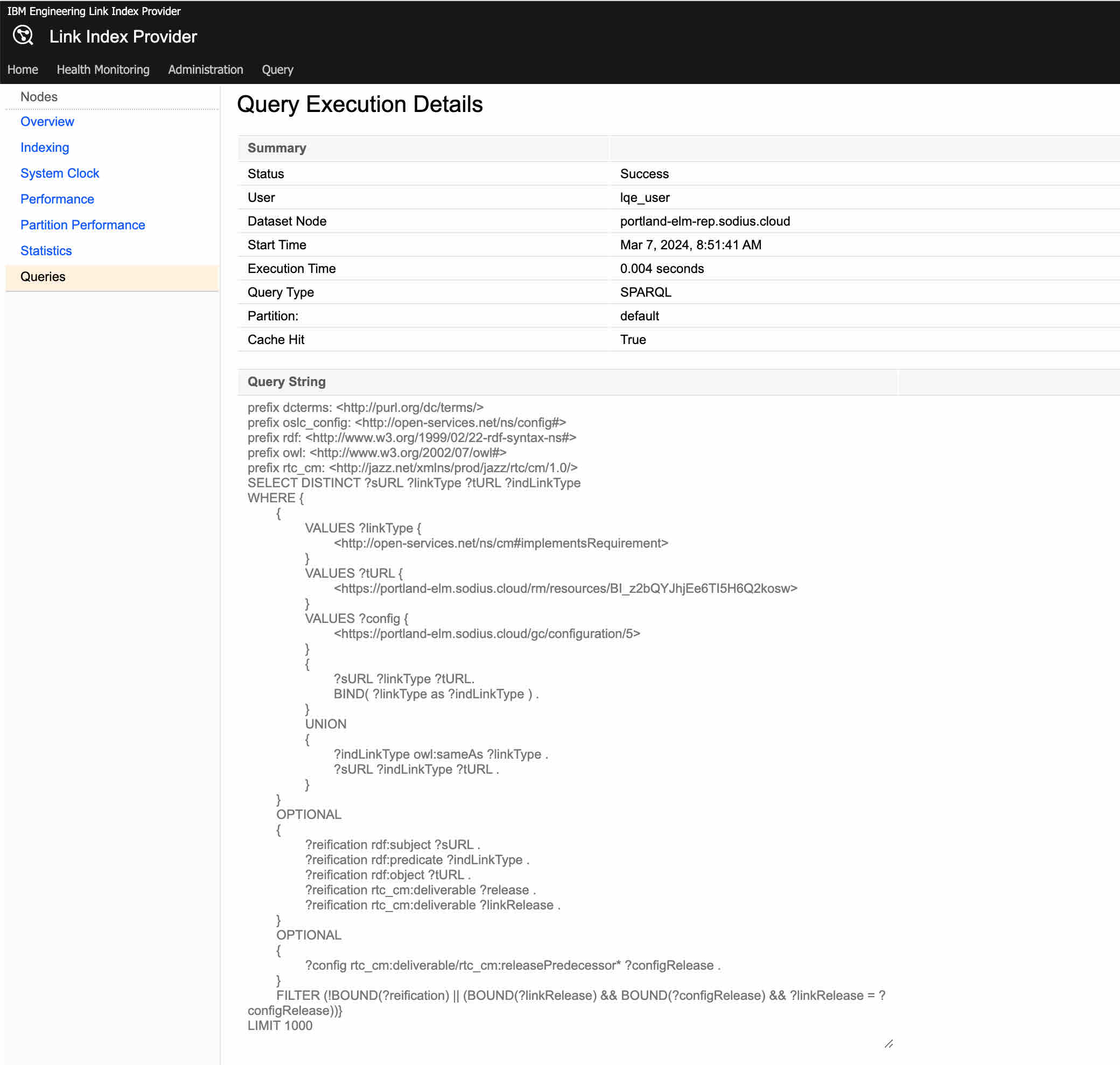
It is a form structure with only the link I am interested in (rather than the more broad search that DNG is doing for users).
Feel free to experiment and understand more about the discovery tools in IBM ELM.
When Discovery can be unsuccessful
If Discovery doesn’t return the data expected, it is because of one of the following
Data isn’t accurate (examples … missing versions in Jira or GC)
Data isn’t up to date in LDX (paused or missing data sources)
See our article on inspecting the contents of LDX to understand better where the failure may have occurred Checking the Contents of LDX