Following is an introduction on how users access data and what security controls are in place when using OSLC and in particular OSLC with IBM ELM.
OSLC is predicated on a secure connection between applications. It focuses on providing information only to those that have permission to see artifacts. It does that with a limited model of storage and the usage of Oauth to enable a server to request information on behalf of a specific user so that the permission model can be retained. So let's look at these items in details.
Link Storage
In OSLC we only store locally a limited amount of information. We don't sync information, but rather dynamically retreive this information from the remote server. We only store the URL to the artifact, the title of the artifact (and even in Jira we can restrict this) and the relationship. Any other information we retrieve is based on authentication access and dynamic retrieval. And in some cases even the backlink is not stored locally (common with IBM ELM) and we perform a discovery (query) to retrieve link information (more on this later).
Securely Accessing Data
There are two ways remote data is going to be presented to a user from the remote server.
Server to Server
When using OSLC tools it is common to get remote tool login prompts. What this is doing is following the Oauth standard so that your local server has a token to request remote content on behalf of your user. This means the remote server knows which Id is requesting and only shares information they are allowed to see. While this Oauth dance to obtain the token is complex, the basic concept is that a server prompts a user to authorize access to the remote server. The remote server (provider) challenges a user to authenticate, and then provides a token to the local server (requestor) to use for accessing content. This can be only done between specific servers and why there is a Friend/Consumer relationship between these servers. For the details of oauth1 you can review https://oauth.net/core/1.0a/ .
What this token allows is that the server can request title updates (and icons) for links. It can perform queries to discover other incoming links. It can identify what projects are available to link to. All of the types of behaviors that users expect from this tight integration. And best of all it is secure and using that specific user's id. As well it gets details on where rich previews are located, creation dialogs, and selection dialogs.
These are the majority of the interactions, however there is another method used in OSLC to make the integrations feel seemless.
Embedded iFrame
Embedded iFrames are the method that OSLC chooses to show remote content locally in a tool. Effectively it is a web method of framing the content from one website into another. The benefit is that it appears a blended and consistent content. There are some challenges to this approach but we address that in our multi-domain architectures.
When we use iframes, it is your current authentication status that allows that remote content to be presented. The servers are not communicating and brokering this information, but rather it is directly requested by your browser and rendered.
While two different methods are used to retrieve content, both are secure and depend on your user's authorization to request information.
Example
We can use an example to explain these types of interactions. From a generic view, the browser on your client is talking to both servers, and then internally the servers are talking to each other (and using your token). The simplified look is the following:

In your browser window we can identify a few more items.
Prior to the oauth dance, the DNG server does not have permission to access Jira resources. We only see the URL for the Jira artifacts that are linked to DNG.
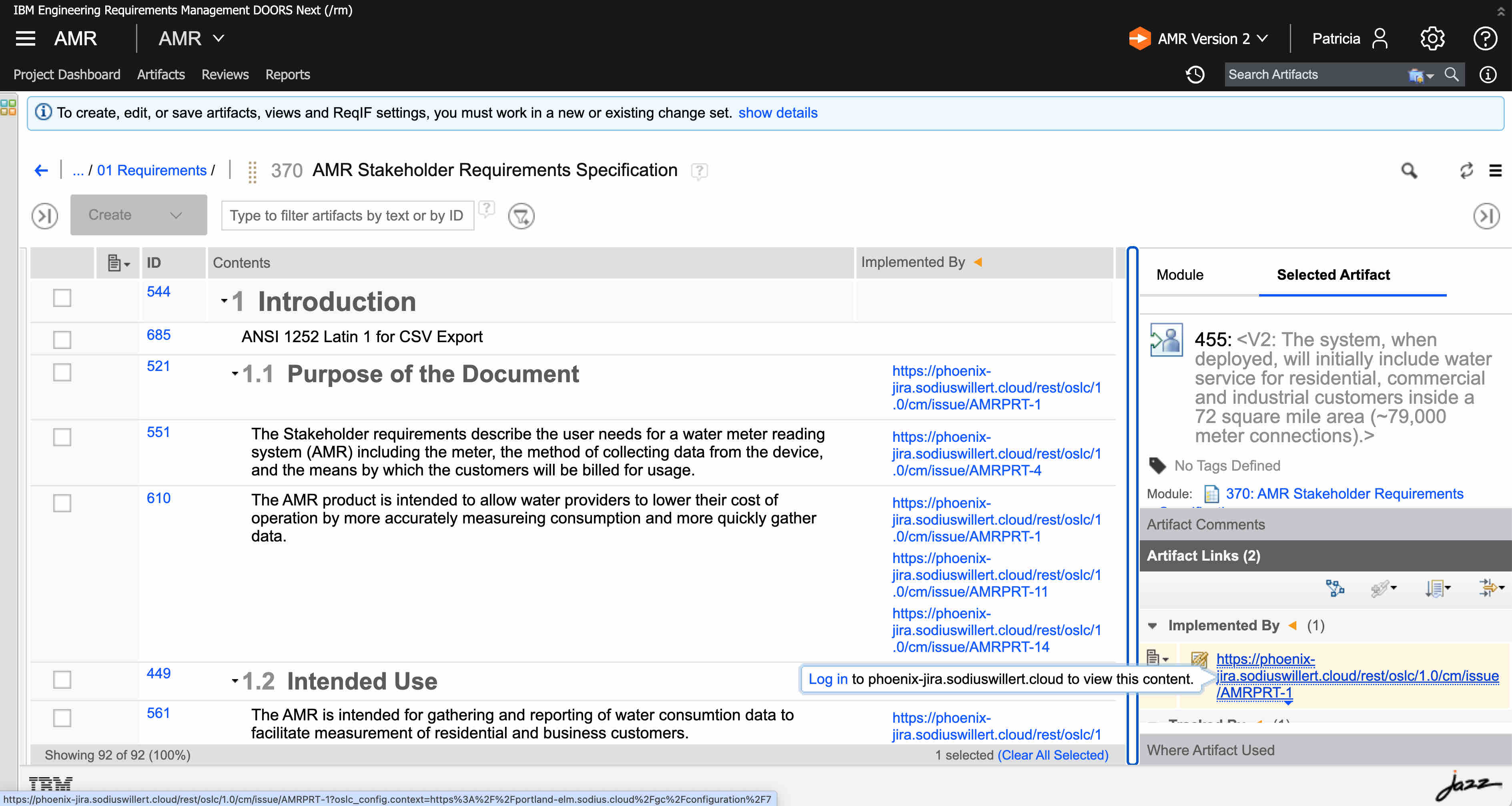
After we click the login button, we are prompted for our Jira credentials and then a token is used to DNG to request Jira contents on behalf of our user Id. In this case the content returned is a compact, that provides (simplified) a description of the current title, icon, and location (URL) to retrieve a rich preview.
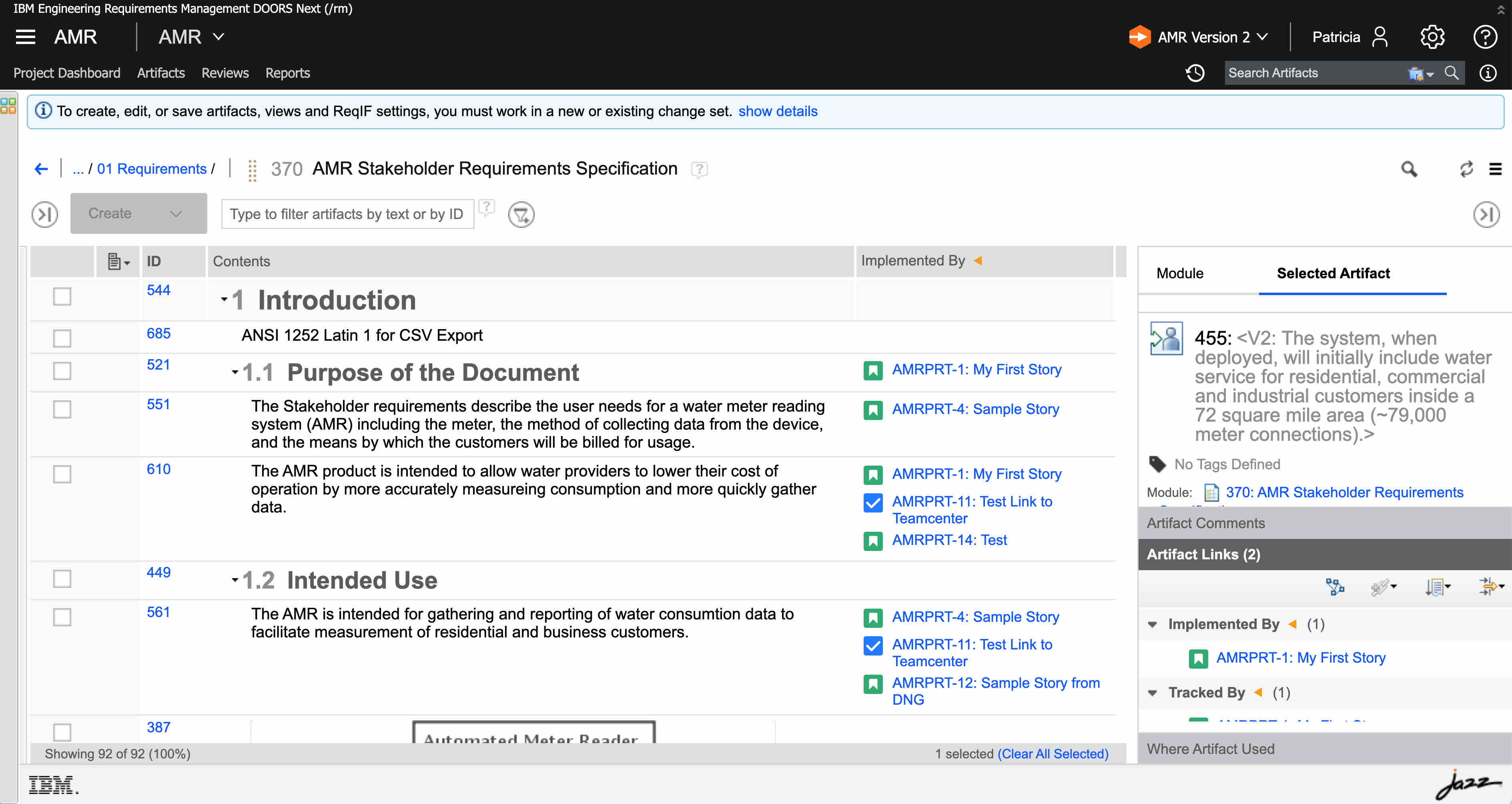
And finally if we do a rich-hover, these are frame issued by DNG, but the embedded data is a web URL accessed directly by your browser pointing to Jira. The Blue is the frame produced by DNG, the red is the content embedded from Jira by your browser.
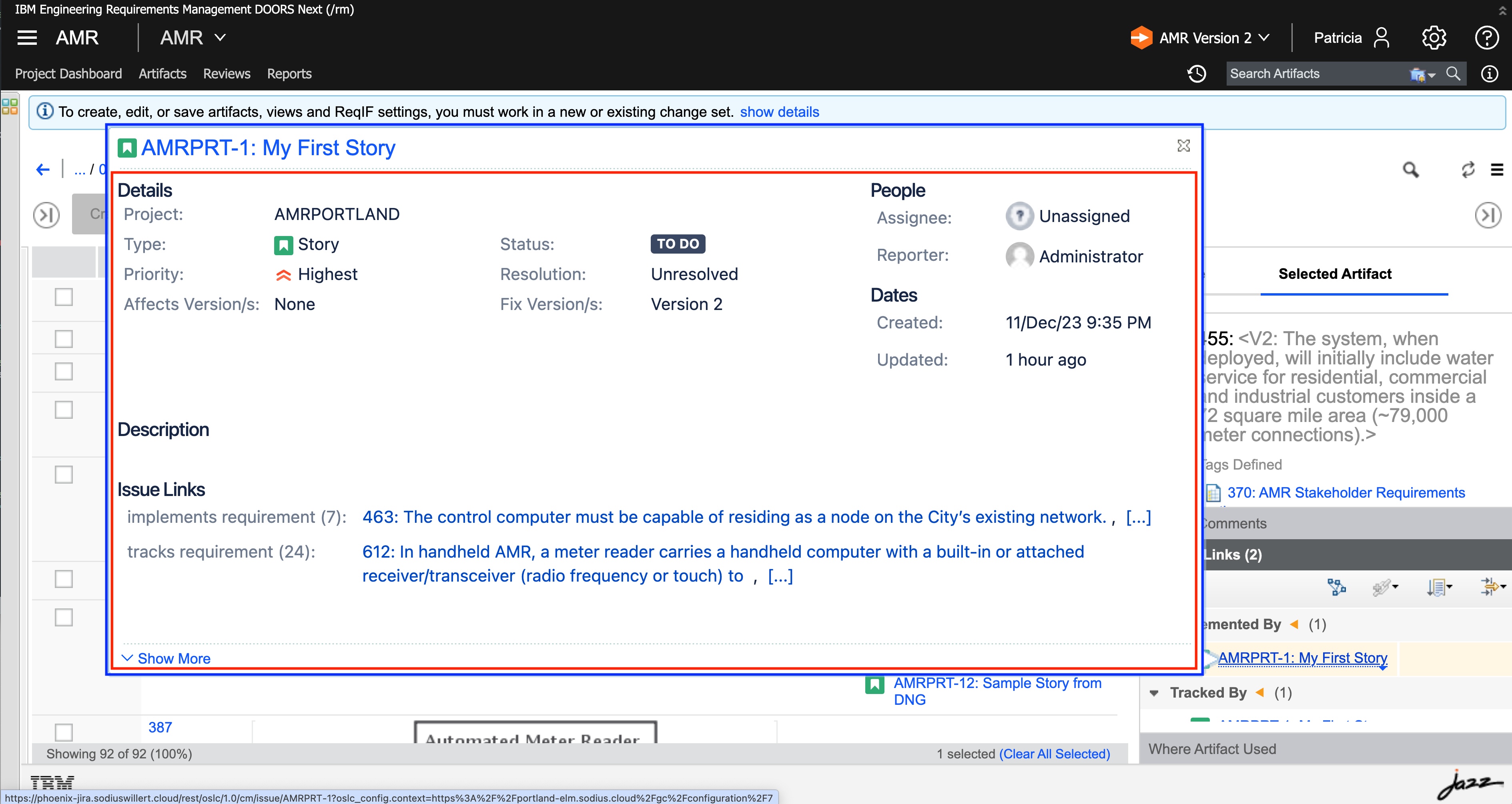
While a user does not observe all the details, the interactions are secure and happening within their permissions in the respective tools for the current user.
Discovery (Finding Links you do not own)
In most situations a link has a natural owner. This is the starting point for a link. And this is why we store links on the starting point (like most Jira links to ELM).
For many, the goal is to have bidirectionally. However, storing links on both ends is a management challenge (especially when doing configuration managed projects). The alternative of storage, is that the reverse navigation can be thought of as a discovery process. We can think of this as a natural query flow from a target asking the simple question, "are there any artifacts that are linked to me?" While we can use this concept in many tools, IBM ELM is the most prevalent in leveraging it.
In practice there are two ways that these discoveries are performed today.
OSLC Query
This is the most natural way that these queries are performed on OSLC. It is a simple Query service provided by the remote OSLC service. It uses the secure connection between servers using a user token to request information. The results are filtered by the permissions of the user in the remote system because of the user is known.
The downside of OSLC query is that it tends to be slow and has the potential to require multiple requests to a repository. The general pattern that is performed is that series of queries (one for each project association that could have these links) are performed. This leads to potential performance degradation (lots of requests) and missing links (if a project does not have associations to the all remote projects with links).
Indexes
An alternative to using OSLC query, is to use an alternative index and query service. An index is required to read all the projects in all repositories to create a single source for querying. A single query can now provide results from ALL projects, and ALL repositories. The downside of this approach is the delay of discovery based on when the index has been updated. And this index also erodes the traditional permission model in OSLC since data is now indexed/stored outside of the owning repository.
This provides both an opportunity an a challenge that each solution must navigate.
OSLC Tracked Resource Sets
While OSLC does not mandate an index service, they do define how an index service may gather data. This is the Tracked Resource Set specification. Very simply, this defines a set of services that allows an indexer to know what resources to index as well as what resource have changed since the last time it checked. This affords the ability of the indexer to identify what artifacts it wants to index, and what data from those artifacts it wishes to store.
The consumer of a TRS feed will read the feed of artifacts and changed artifacts. It will then request details on each of these artifacts and store/index the attributes that the index believes that are valuable.
TRS and Indexes with IBM ELM
IBM ELM supports this Tracked Resource Set standard, and expects all repositories connecting to ELM to support it as well. For example, you can see in DOORS Next the provision of both a RM resource feed as well as a Process (Project feed).
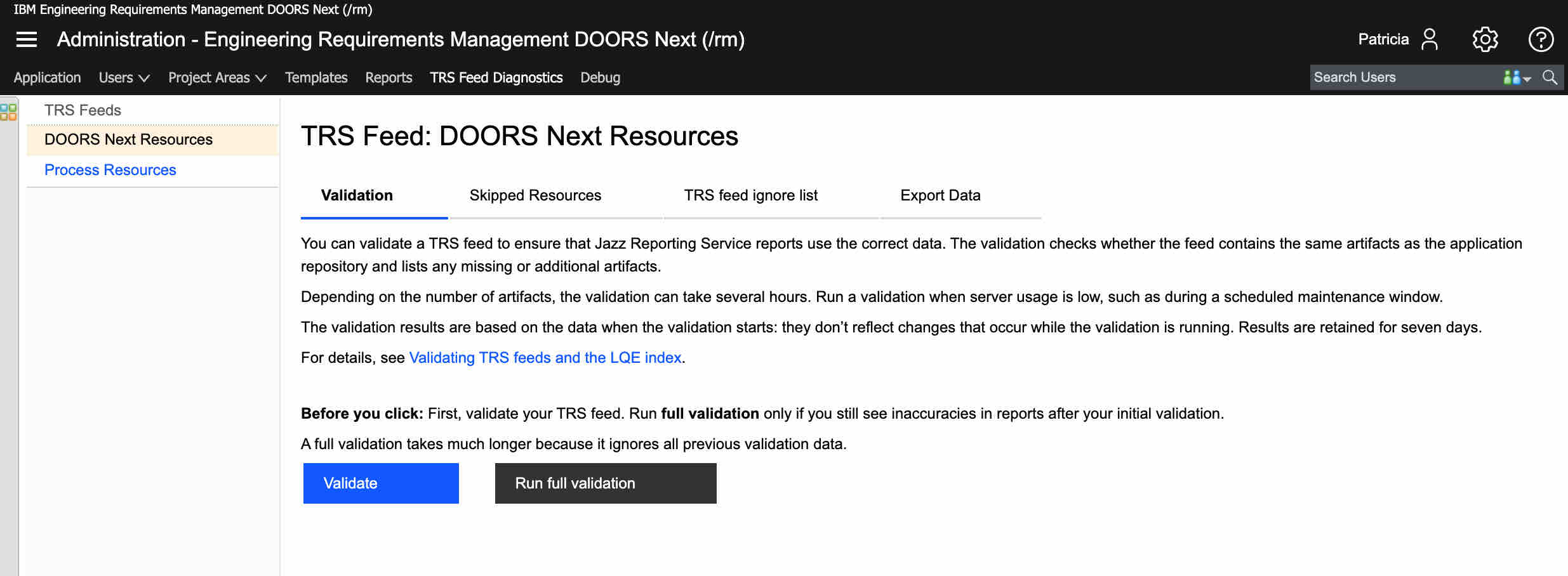
To read these feeds, IBM uses two indexing services. LQE is their reporting index that allows report creation for all data provided to it. And LDX is their link query index that serves queryable service used by DNG, ETM and others to discover incoming (backlinks) to their artifacts. These indexes will attempt to update themselves every 60 seconds from each of their data sources, but it might vary based on the volume of data.
For example this LQE system has 17 data sources. This includes the standard IBM ELM data sources as well as data sources from SodiusWillert extensions.
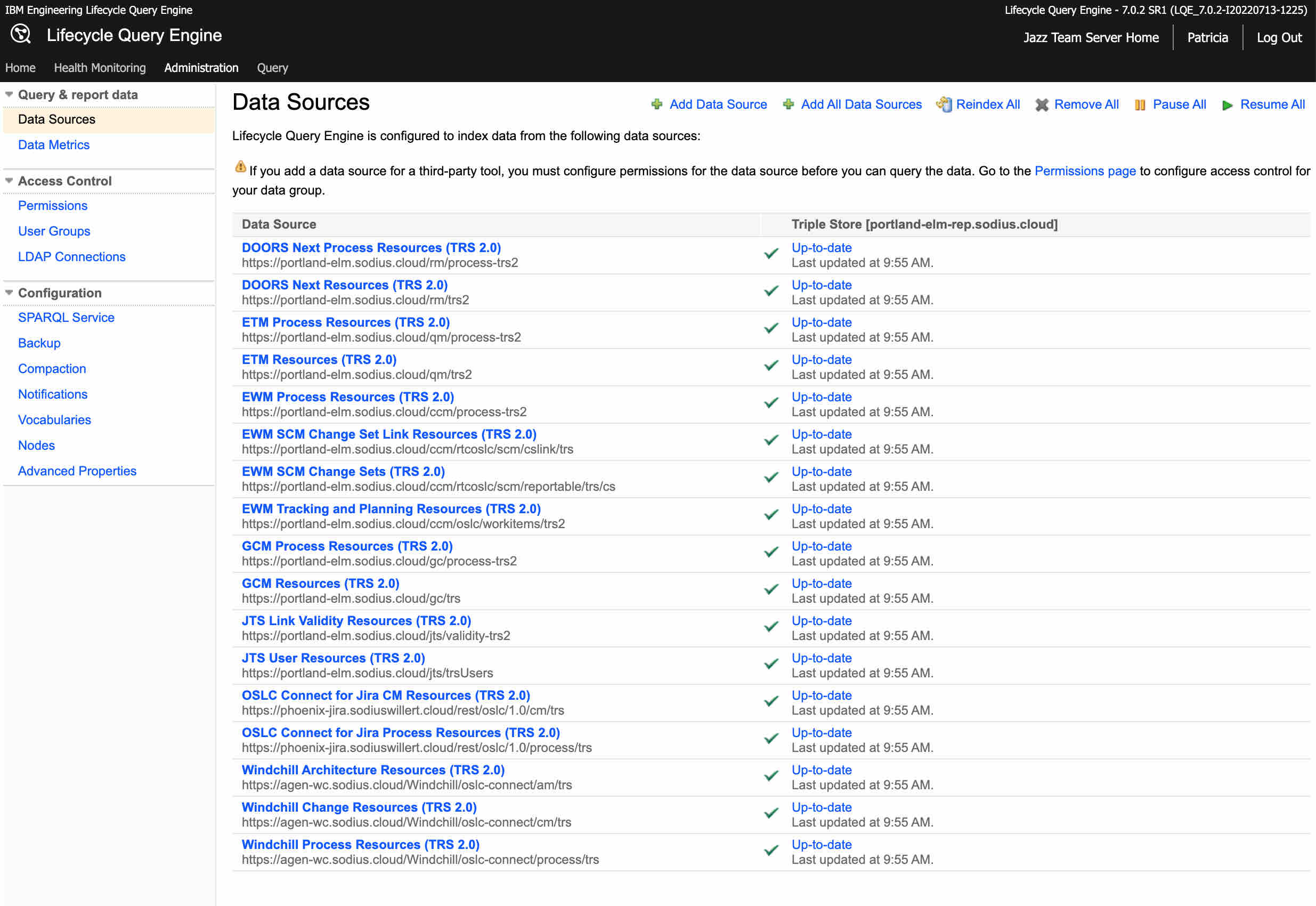
The 60 second update window is to provide for timely data but not overburden the data sources.
TRS Provider (Example OSLC Connect for Jira)
A TRS provider is responsible to provide the list of artifacts in the repository and identify artifacts that have been changed.
Our OSLC Connect for Jira is an example of this service. It provides two feeds. The first is the set of process resources which is effectively the containers/projects that the resources are grouped into. The second is the set of Change Management resources (the Jira issues) that are contained in the repository.
Our administration page provides some more details.
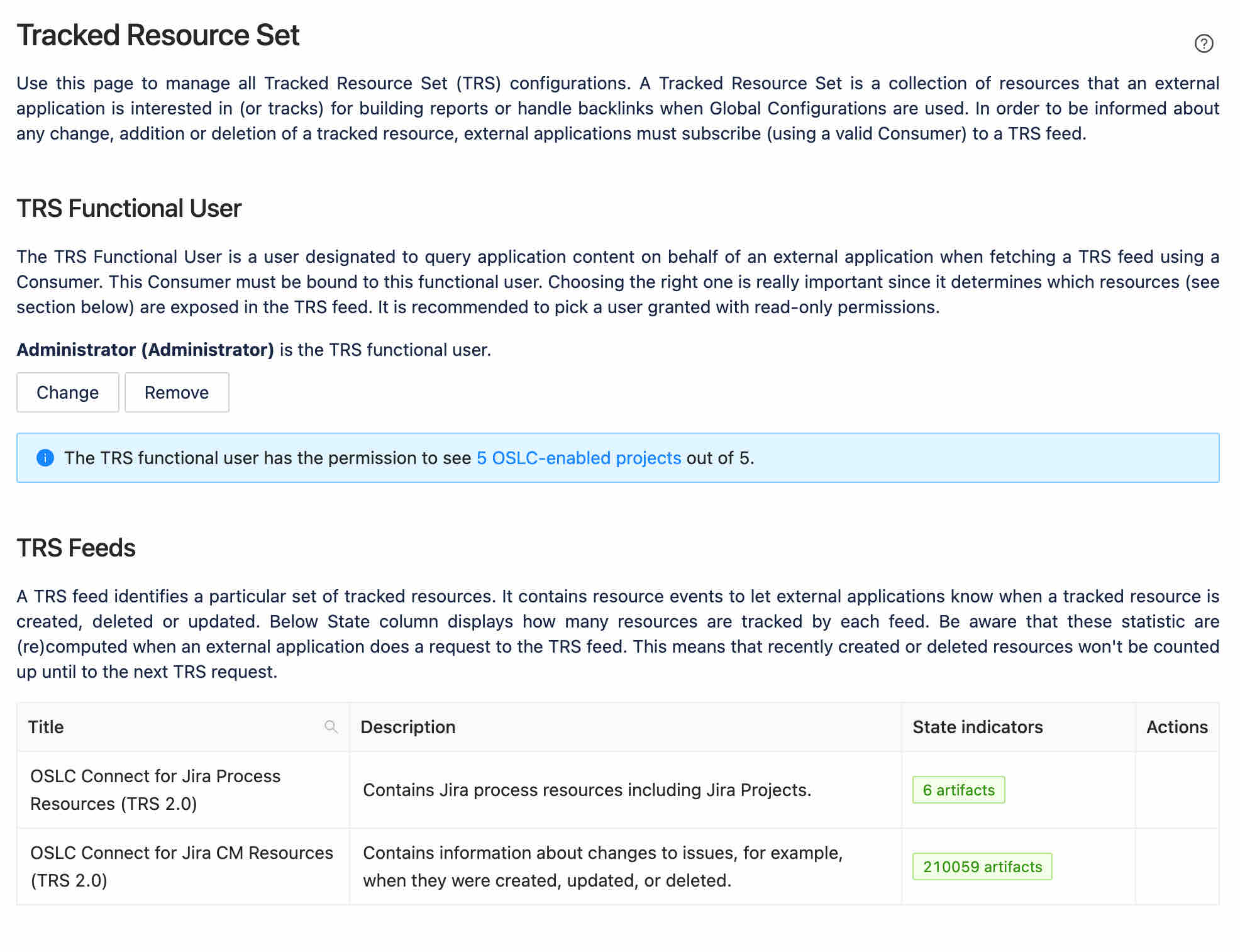
A TRS has a functional user. This is the local user that is used for permissions to access and monitor artifacts for change. It is critical that this user has broad permissions (we recommend an administrator) as this is the only way that all the resources can be monitored and reported to an index. Having less than Administrator status risks missing projects or change resources that would result in inaccurate reports or link discoveries in IBM ELM.
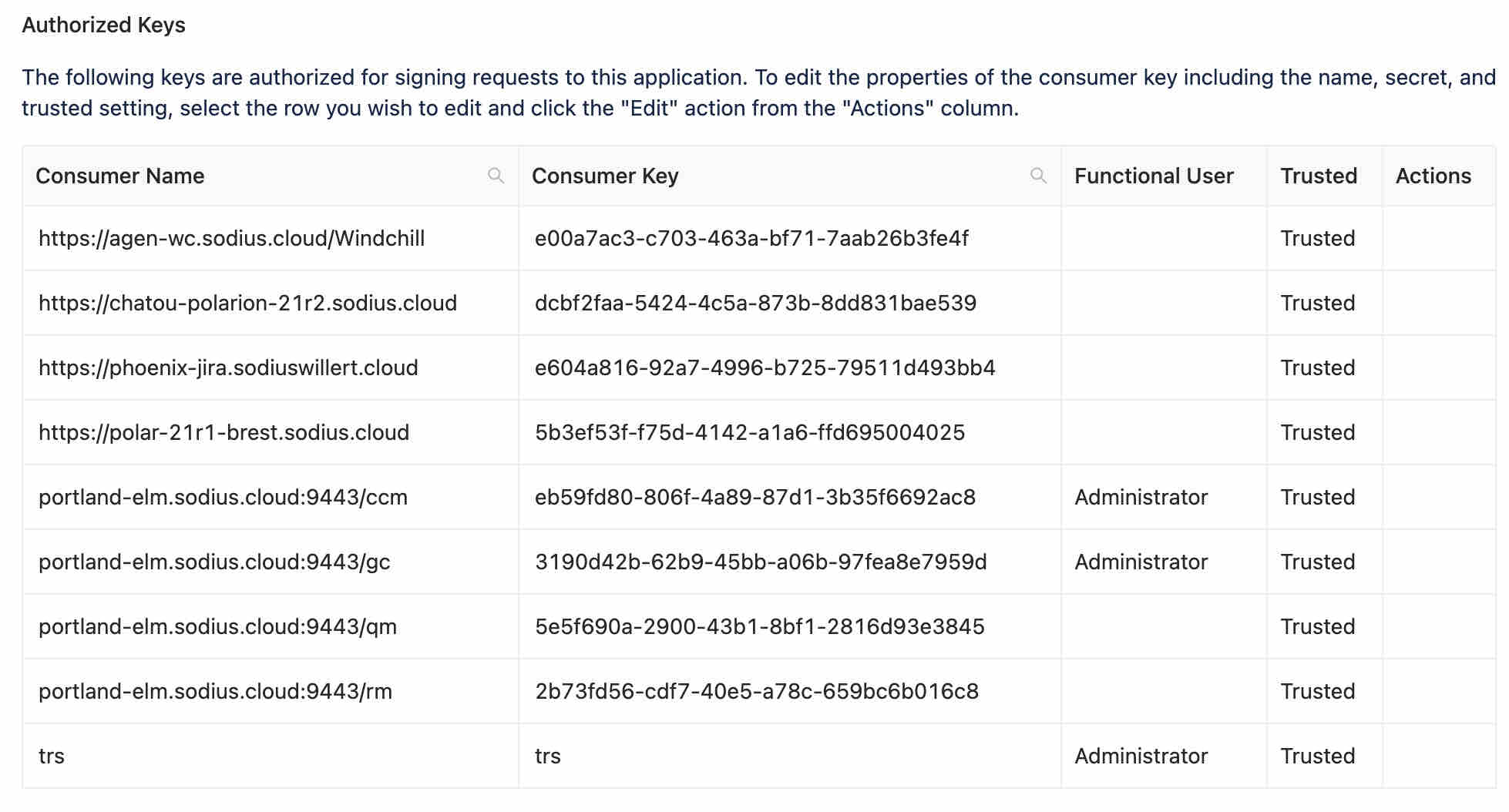
A TRS reader, like LDX, will use Oauth to access the resources in a repository. This means that they will read the feed to know what resources to index. Secondarily they will need to read these resources to gather the details on the resources. This permission on the access of the resources is set on the TRS consumer. For example you can see my consumer for TRS that I have declared (used for LDX and LQE) using the same Functional User (Administrator). This is required so the Index can read both the TRS as well as the artifacts it references.
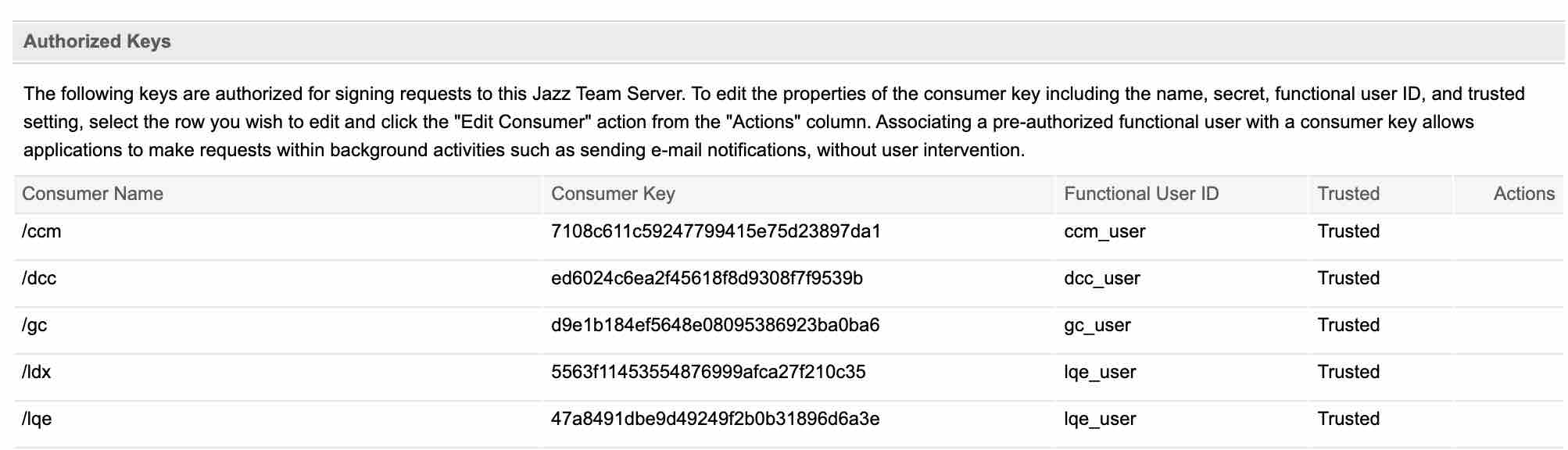
Note the IBM ELM tools do this but it is a little more hidden to the users, as it is setup at installation time. You can see these functional users in the Consumers in JTS. Note the lqe_user on LDX and LQE as the functional user.
LDX/LQE Architecture (and TRS)
The pattern of replicating data from a remote repositories into an index requires some review of the permission models and access models. This is because once the data is moved to a different repository, a different permission model is applied. LQE and LDX follow different patterns of securing the data and managing access.
LDX Security Model
The role of LDX is not to provide data, but rather simply to share references that can be later explored. It stores a limited set of details about a resource including its type and its outbound links, but it excludes information like title or description about the resource. As such a minimized security model is applied. To access information from LDX a user must be an authorized IBM ELM user. Fortunately LDX only provides details such as link types and URLs without revealing data about the artifacts. For example the folloiwng should be referenced from above. These are the link details that ELM retrieved from LDX about a link existing prior to authenticated to Jira to reveal the details.
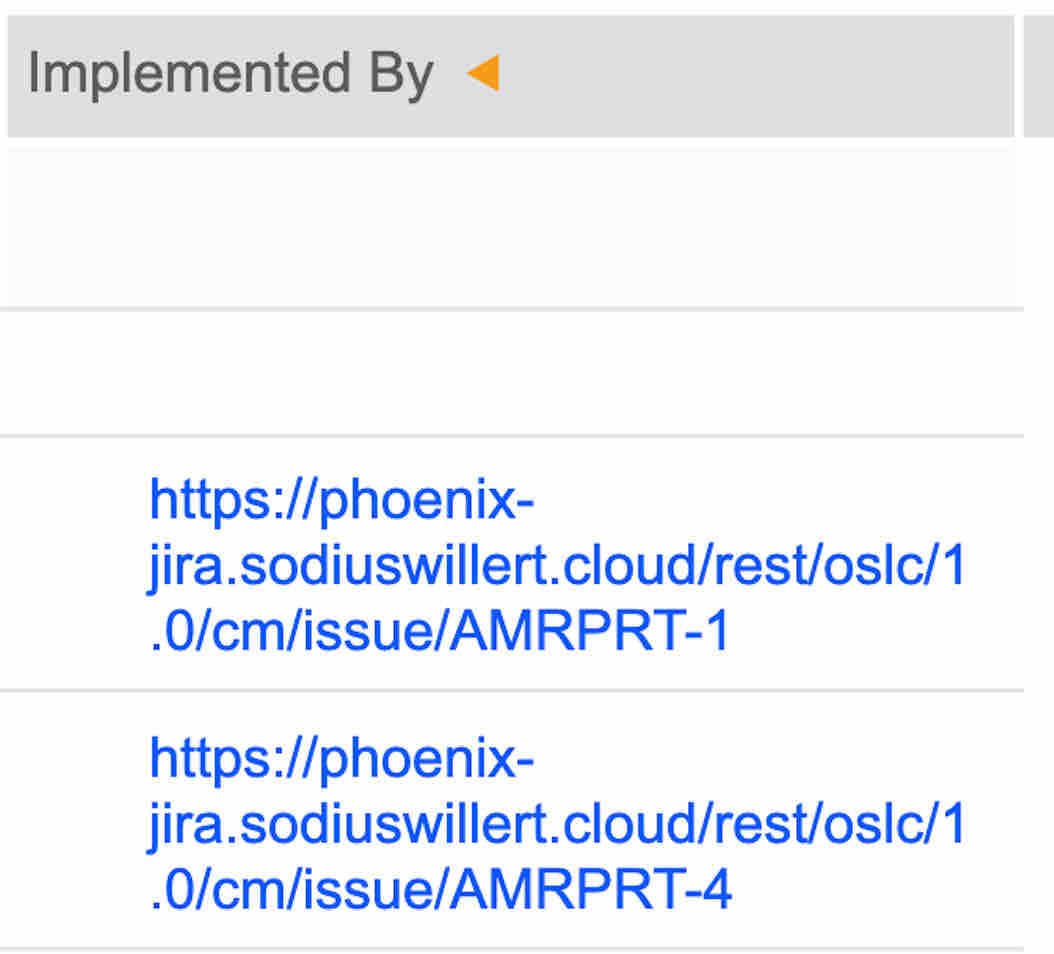
In most cases there is no issue in sharing such URLs.
LQE Security Model
The role of LQE is to do reporting. It is used by both Report Builder and Engineering Insights to create their reports. This is done to speed reporting and not requiring these tools to go to all of the remote repositories to gather data. While in Jira we control what data is made available, once that data is in LQE, it is the responsibility for LQE to control the access.
What LQE does to address this gap is provide a new permission layer over the data stored in LQE. This is a hierarchical model that allows the definition of permission rules on a per repository and per project basis. For example the following in the LQE Admin pages.
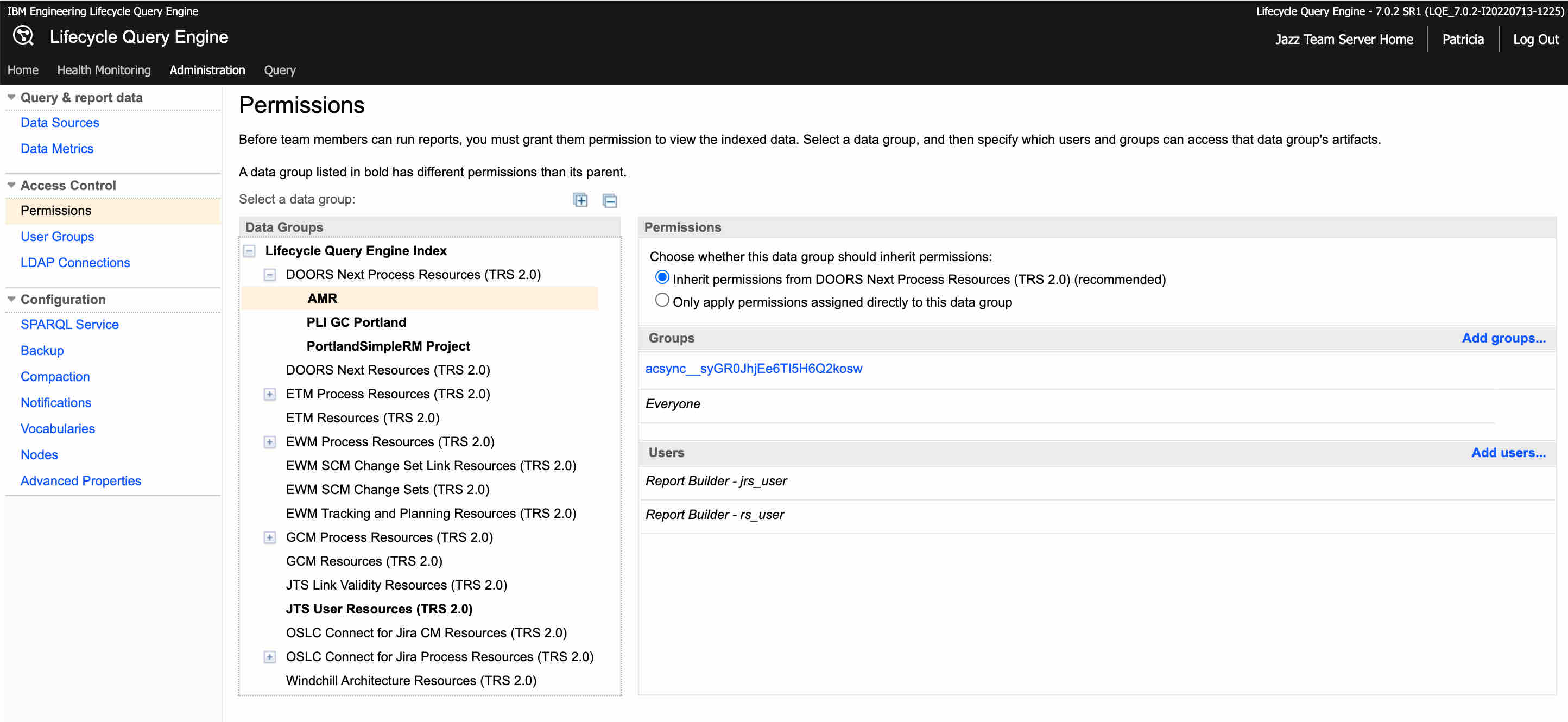
This allows a definition of the users that have access of a project for reporting. What is apparent is that the access rules for reporting are not the access rules for accessing a project. However, IBM ELM tries to make this easier for IBM ELM projects with the default “async__” groups that are created. On closer inspection of these groups you will see the following:

This shows that these are automatically created groups created from the access groups of the projects. So as users are added or removed from the AMR project in DNG, this group will be updated.
LQE Security Model with non ELM tools
While this model works for ELM tools, the challenge is that these are not available for non-IBM tools. We have two challenges to this.
First, there is a missing public/standard API for adding and managing these group settings for project access.
Second, there is the dependency of using the same user/authentication authority. These permissions are all stated as related to IBM ELM users, so the need would be, for example, mapping Jira user ids to IBM ELM ids.
So how to manage security with Jira data with IBM ELM? There are a couple of suggestions we can make.
For those with minimal security concerns, you can make Jira available to all ELM users for reporting. This ensures they have ELM access to report on data.
For those with closely paired projects, you can reuse the already established “async” groups that ELM is maintaining for your Jira projects. This would mean that associated Jira projects to DNG projects would allow those DNG users (and only those DNG users) to report on the Jira data.
For those with very strict reporting, they will need to create and manage custom groups for access to Jira data.
You are able to secure data, it may require a little more work than native ELM data.
'